
























通专融合AGI




平台整合了专业智能体、海量科研数据及实验设备,能为全球研究者提供从假设到验证的一站式科研支撑。
平台整合了专业智能体、海量科研数据及实验设备,能为全球研究者提供从假设到验证的一站式科研支撑。
高效科学助理,带你玩转一站式 AI 实验室
50 家专业机构
200+ 科学数据集
通过平台集成算力闭环
实现数据分析与模型训练
100+ 厂商设备
200+ 科学工具
科学上下文协议 SCP 支持
实现干湿实验智能执行


AI谱学大模型,助力研究者更高效、更精准地探索微观世界,推动物质科学研究创新。
AI谱学大模型,助力研究者更高效、更精准地探索微观世界,推动物质科学研究创新。
AI+EPR
秒级解谱、识谱寻源


具备强大理解和分析能力的种业大模型,降低了种领域的学习门槛,助力提升从业者的研究、实践效率。
具备强大理解和分析能力的种业大模型,降低了种领域的学习门槛,助力提升从业者的研究、实践效率。
结合书生·浦语2.0
生物育种垂直领域
品种选育、农艺性状、推广区域、栽培技术


全面由国产新兴算力异构互联技术支撑,完整训练而出的全能多模态生成大模型。
全面由国产新兴算力异构互联技术支撑,完整训练而出的全能多模态生成大模型。
异构混训
效率达97.5%
提升1.6倍
虚实结合物理智能


构建仿真、数据、训测三大引擎,一站式破解具身智能从数据、训练到实际应用的全链条难题,推动具身大脑从 “碎片化开发” 迈向 “全栈化量产”时代。
构建仿真、数据、训测三大引擎,一站式破解具身智能从数据、训练到实际应用的全链条难题,推动具身大脑从 “碎片化开发” 迈向 “全栈化量产”时代。
一脑多形
实现开发一套模型
即可适配10余种机器人形态
训测一体
全任务工具链,一键启动模型训练
快速部署具身大脑开发
虚实贯通
融合真机实采与虚拟合成数据,数采成本相比前代方案进一步降至0.06%

生成式世界模型AETHER全部由合成数据训练而成,不仅在传统重建与生成任务中表现领先,更首次赋予大模型在真实世界中的 3D 空间决策与规划能力,可助力机器人完成目标导向的视觉规划、4D 动态重建、动作条件的视频预测等复杂任务。
生成式世界模型AETHER全部由合成数据训练而成,不仅在传统重建与生成任务中表现领先,更首次赋予大模型在真实世界中的 3D 空间决策与规划能力,可助力机器人完成目标导向的视觉规划、4D 动态重建、动作条件的视频预测等复杂任务。
目标导向视觉规划
4D 动态重建
动作条件视频预测
安全可信AI


评测体系


面向大模型的开源方和使用者, 提供开源、高效、全面的大模型评测开放平台。 为大语言模型、多模态模型等各类模型提供一站式评测服务。全面量化模型在知识、语言、理解、推理和考试等五大能力维度的表现,客观中立地为大模型技术创新提供坚实的技术支撑。
面向大模型的开源方和使用者, 提供开源、高效、全面的大模型评测开放平台。 为大语言模型、多模态模型等各类模型提供一站式评测服务。全面量化模型在知识、语言、理解、推理和考试等五大能力维度的表现,客观中立地为大模型技术创新提供坚实的技术支撑。
CompassHub
评测集社区:提供高时效性,高质量评测集
CompassRank
性能榜单:发布权威榜单,洞悉行业趋势
CompassKit
评测工具:支撑高效评测,支持能力分析

医疗大模型应用检测验证中心
全国首个医疗大模型应用检测验证中心,打通 “训、评、用一体化”链路,为产业应用提供方向牵引与安全保障,促进生态发展。检测验证中心已完成上海12家医院的医疗大模型应用场景评测,规范产业和促进产业升级。
医疗大模型应用检测验证中心
全国首个医疗大模型应用检测验证中心,打通 “训、评、用一体化”链路,为产业应用提供方向牵引与安全保障,促进生态发展。检测验证中心已完成上海12家医院的医疗大模型应用场景评测,规范产业和促进产业升级。
覆盖国家《卫生健康行业人工智能应用场景参考指引》指导文件中32个场景辐射的10多个亚场景应用评测
基础平台

人工智能开放计算体系,可支持国产多芯片异构、跨域的训推一体化工具链,旨在搭建对硬件芯片与深度学习软件框架进行适配的桥梁,共建开放的软硬件适配生态。
人工智能开放计算体系,可支持国产多芯片异构、跨域的训推一体化工具链,旨在搭建对硬件芯片与深度学习软件框架进行适配的桥梁,共建开放的软硬件适配生态。
开放、完备、高效、简单
千公里级跨域混训
二十余家合作伙伴
编译通信极致性能加速


数据开放平台,为开发者提供全链条的AI数据支持,应对和解决数据处理中的风险与挑战,推动数据要素对大模型领域全面赋能。
数据开放平台,为开发者提供全链条的AI数据支持,应对和解决数据处理中的风险与挑战,推动数据要素对大模型领域全面赋能。
数据标准化、多维灵活检索、数据可视化、免费高速下载
15万+人
注册用户
400万+次
累计提供数据获取服务
7700+个
数据集
行业应用
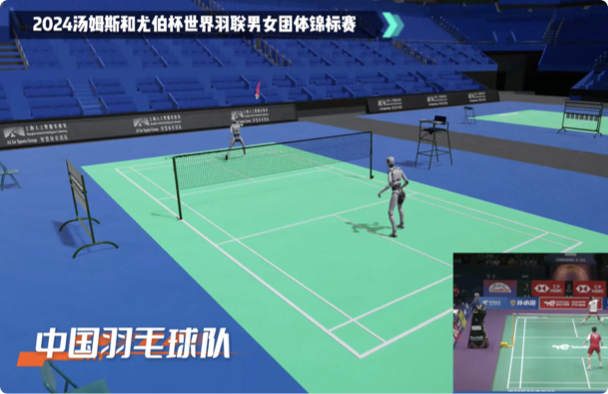

国内首个AI体育技战术大模型,仅基于体育运动的视频画面,即可实时获取并分析出关键参数信息,为体育比赛直播及运动员竞技水平分析提供AI支持。
国内首个AI体育技战术大模型,仅基于体育运动的视频画面,即可实时获取并分析出关键参数信息,为体育比赛直播及运动员竞技水平分析提供AI支持。
仅基于单路电视PGM信号(最终播出信号)即可获取技战术指标
动态时间切片技术(Dynamic Figure Out)


基于央视听媒体大模型(MediaGPT),与中央广播电视总台联合制作首部AIGC系列动画片《千秋诗颂》,国内观众超1亿,触达海外观众11亿,英、西、法、阿等10余个语种版本,同步在全球70余家主流媒体播出。
基于央视听媒体大模型(MediaGPT),与中央广播电视总台联合制作首部AIGC系列动画片《千秋诗颂》,国内观众超1亿,触达海外观众11亿,英、西、法、阿等10余个语种版本,同步在全球70余家主流媒体播出。



